
Proyecto STORJ Observatory
1. Qué es Storj a nivel global
Storj es una red de almacenamiento distribuido. En lugar de guardar los archivos de un cliente en un único centro de datos, Storj divide los datos en piezas cifradas y las reparte entre muchos nodos independientes.
Desde el punto de vista del cliente, Storj se comporta como un servicio de almacenamiento compatible con S3: el cliente sube datos a un bucket y los recupera cuando los necesita. El cliente no ve los nodos individuales ni sabe qué operador concreto conserva cada pieza.
Desde el punto de vista del operador de nodo, el trabajo es distinto: aportar disco, conectividad, disponibilidad y estabilidad. El nodo recibe fragmentos cifrados, los almacena, responde a auditorías y sirve datos cuando la red los solicita.
La red se apoya en varios satélites. Cada satélite coordina almacenamiento, auditorías, pagos, reputación y tráfico. El operador de nodo no controla esa lógica; solo ve los efectos: ingress, egress, espacio usado, trash, auditorías, suspensión, held amount y pagos.
2. El experimento en Nexus
El experimento parte de un nodo Storj montado en Nexus usando Docker.
Contexto técnico:
- Nodo Storj en contenedor Docker.
- Disco dedicado recuperado de una antigua caja QNAP.
- Capacidad física del disco: 2 TB.
- Límite configurado para Storj: 1,8 TB.
- Puerto público principal: 28967 TCP/UDP.
- Dashboard local: puerto 14002.
- Wallet configurada con soporte ZKSync.
- Nodo conectado a cuatro satélites: saltlake, ap1, us1 y eu1.
El objetivo inicial no era montar una infraestructura rentable, sino observar el comportamiento real de una red distribuida moderna usando un recurso ya disponible: un disco que estaba sin uso.
Durante mayo el nodo pasó por varias fases:
- Fase de llenado: mucho ingress, subida rápida del espacio usado.
- Fase de saturación: el disco llegó al límite de 1,8 TB e incluso apareció overused.
- Fase de corrección: la red dejó de empujar tantos datos nuevos y empezó a limpiar trash.
- Fase madura: el nodo quedó prácticamente lleno, con menos ingress y más egress.
- Fase de observación económica: los pagos son bajos, pero el token recibido permite seguir la evolución del valor de STORJ.
El experimento confirmó que el nodo funciona, que la red tiene demanda real y que el comportamiento cambia claramente cuando el disco está lleno.
3. Hipótesis surgidas durante la observación
3.1. Nodo vacío frente a nodo lleno
Un nodo vacío sirve principalmente para recibir datos. Eso genera mucho ingress, pero el ingress no es la parte más interesante económicamente.
Un nodo lleno puede pasar a comportarse como repositorio: almacena datos ya colocados y empieza a servirlos cuando los clientes los solicitan. En esa fase el egress gana importancia.
Hipótesis:
Un nodo pequeño pero lleno de datos útiles puede ser más interesante que un nodo grande parcialmente vacío.
3.2. CurrentMonthExpectations
La métrica currentMonthExpectations llamó la atención porque no parecía seguir únicamente una extrapolación lineal del tráfico visible.
La hipótesis construida durante la observación es que Storj dispone de métricas internas no visibles para el SNO:
- qué piezas tiene el nodo;
- qué clientes dependen de esas piezas;
- cuántas copias existen;
- patrones históricos de acceso;
- reparaciones previstas;
- distribución por satélite;
- probabilidad futura de egress.
Por eso, cuando el disco está lleno y el egress sube, esa expectativa puede seguir aumentando aunque el ingress esté casi parado.
3.3. Riesgo económico para los SNO
El experimento también reabrió una reflexión sobre la sostenibilidad económica de Storj para operadores de nodo.
El usuario ya había operado un nodo Storj anterior con varios discos en RAID10, con ingresos aproximados de 50-60 euros al mes. Ese nodo quedó descalificado tras el fallo de un disco y el tiempo necesario para reconstruir el RAID.
Comparado con aquella etapa, el nodo actual genera mucho menos, aunque también parte de una inversión casi nula.
Conclusión:
Storj sigue siendo técnicamente interesante, pero la rentabilidad para el SNO puede ser demasiado baja si requiere comprar hardware nuevo. Tiene sentido con hardware amortizado o recuperado; tiene mucho menos sentido como inversión dedicada.
4. Necesidad de monitorización
La observación manual empezó con capturas de dashboard y llamadas API pegadas en el chat.
Comandos y fuentes utilizadas:
-
Endpoint general del nodo: http://127.0.0.1:14002/api/sno
-
Endpoint de satélites: http://127.0.0.1:14002/api/sno/satellites
-
Endpoints individuales por satélite: saltlake, ap1, us1, eu1
-
Información de payout: endpoint de payout del dashboard local
El problema detectado:
Mirar manualmente la dashboard y pegar JSON en el chat sirve para analizar, pero no escala. Se pierde histórico, cuesta comparar periodos y obliga a recopilar datos a mano.
De ahí nace el proyecto de monitorización.
5. Solución propuesta: Storj Observatory
La solución diseñada se llamó conceptualmente Storj Observatory.
Objetivo:
Construir un sistema que capture automáticamente el estado del nodo Storj, guarde snapshots periódicos y permita generar análisis posteriores con SQL, dashboards e IA.
La idea no es solo ver el estado actual, sino conservar memoria histórica.
6. Arquitectura general
Flujo previsto:
Storj API ↓ Collector en n8n ↓ PostgreSQL ↓ Reporter SQL + IA ↓ Dashboards / informes / análisis
Componentes:
6.1. Collector n8n
Un workflow de n8n ejecutado cada 12 horas.
Funciones:
- llamar a los endpoints API del nodo Storj;
- recoger snapshot global;
- recoger datos por satélite;
- normalizar valores;
- insertar datos en PostgreSQL;
- detectar satélites nuevos automáticamente;
- evitar depender de capturas manuales.
La frecuencia se planteó flexible: cada 6, 12 o 24 horas. La decisión final no afecta al modelo de datos porque el timestamp created_at define el momento real de cada snapshot.
6.2. PostgreSQL
Base de datos encargada de guardar el histórico.
Principio clave:
Se guardan estados absolutos, no solo diferencias.
Las diferencias, velocidades y tendencias se calculan después mediante consultas SQL usando LAG() o comparaciones entre snapshots.
6.3. Reporter
Capa futura para generar informes automáticos.
Funciones posibles:
- resumen diario;
- resumen semanal;
- detección de anomalías;
- comparación de satélites;
- explicación narrativa con IA;
- preparación de texto para revisión humana.
6.4. IA
La IA no sustituye la base de datos ni las métricas.
Su papel previsto:
- interpretar tendencias;
- detectar patrones;
- redactar resúmenes comprensibles;
- comparar periodos;
- explicar anomalías;
- convertir datos técnicos en narrativa operativa.
7. Modelo de base de datos diseñado
La infografía generada resume el esquema actual de la base de datos.
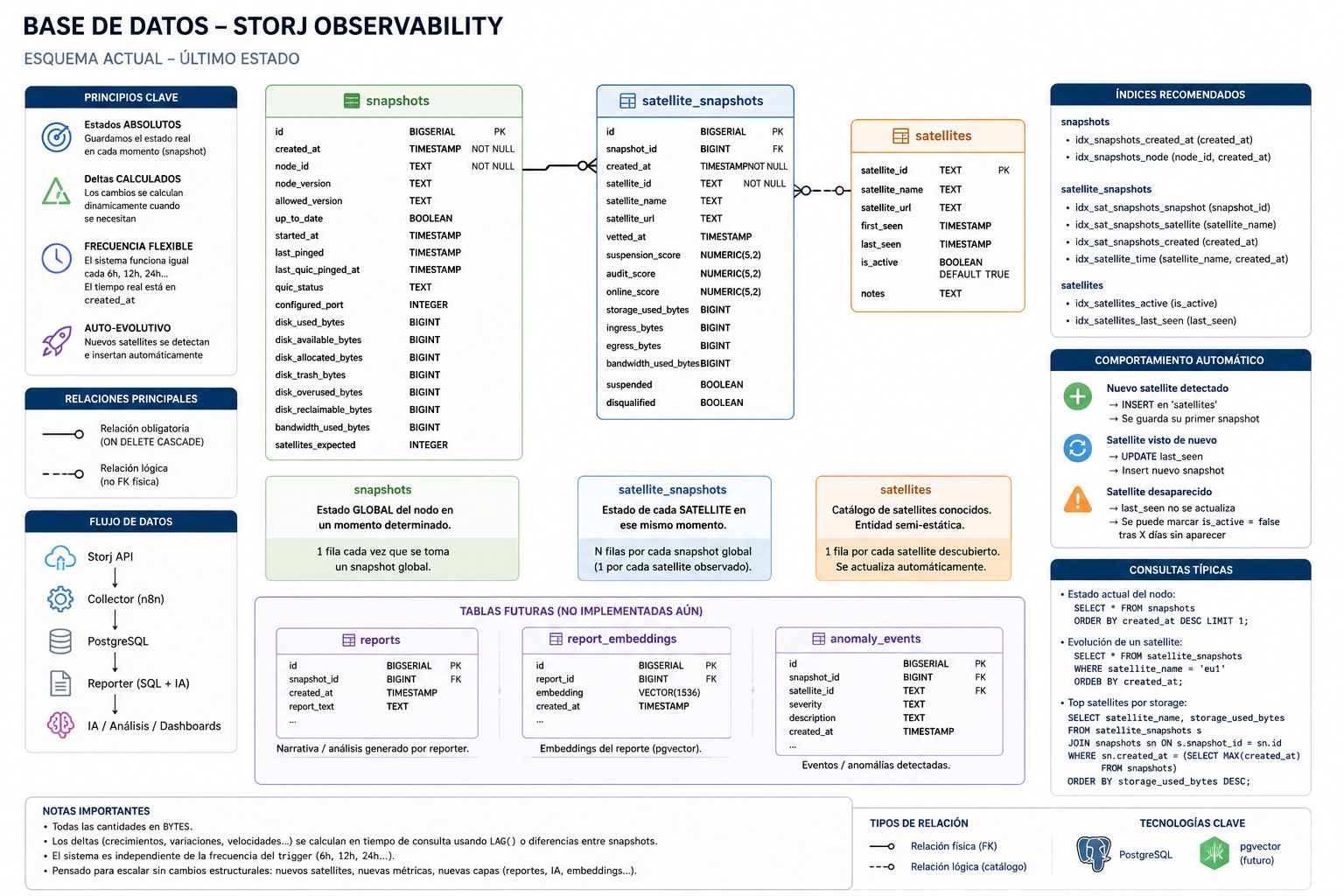
7.1. Tabla snapshots
Guarda el estado global del nodo en cada momento.
Campos principales:
- id
- created_at
- node_id
- node_version
- allowed_version
- up_to_date
- started_at
- last_pinged
- last_quic_pinged_at
- quic_status
- configured_port
- disk_used_bytes
- disk_available_bytes
- disk_allocated_bytes
- disk_trash_bytes
- disk_overused_bytes
- disk_reclaimable_bytes
- bandwidth_used_bytes
- satellites_expected
Cada fila representa un snapshot global del nodo.
7.2. Tabla satellite_snapshots
Guarda el estado de cada satélite dentro de cada snapshot.
Campos principales:
- id
- snapshot_id
- created_at
- satellite_id
- satellite_name
- satellite_url
- vetted_at
- suspension_score
- audit_score
- online_score
- storage_used_bytes
- ingress_bytes
- egress_bytes
- bandwidth_used_bytes
- suspended
- disqualified
Cada snapshot global genera N filas en esta tabla, una por cada satélite observado.
7.3. Tabla satellites
Catálogo semi-estático de satélites conocidos.
Campos principales:
- satellite_id
- satellite_name
- satellite_url
- first_seen
- last_seen
- is_active
- notes
Sirve para identificar satélites nuevos, marcar satélites desaparecidos y mantener un catálogo limpio.
8. Principios de diseño del esquema
8.1. Estados absolutos
Se guarda el valor exacto en cada momento.
Ejemplo:
- disco usado en bytes;
- trash en bytes;
- ancho de banda usado;
- score de auditoría.
No se guardan solo deltas.
8.2. Deltas calculados
Los cambios se calculan después.
Ejemplo:
- crecimiento de disco entre snapshot A y snapshot B;
- variación de egress;
- caída de online score;
- subida de trash;
- velocidad media diaria.
8.3. Frecuencia flexible
El sistema no depende de capturar cada hora exacta.
Puede funcionar cada:
- 6 horas;
- 12 horas;
- 24 horas.
La precisión real la marca created_at.
8.4. Auto-evolutivo
Si aparece un satélite nuevo:
- se detecta;
- se inserta en satellites;
- se guarda su primer snapshot.
Si un satélite deja de aparecer:
- no se actualiza last_seen;
- puede marcarse como inactivo tras X días.
9. Índices recomendados
Para snapshots:
- idx_snapshots_created_at (created_at)
- idx_snapshots_node_id_created_at (node_id, created_at)
Para satellite_snapshots:
- idx_sat_snapshots_snapshot (snapshot_id)
- idx_sat_snapshots_satellite (satellite_name)
- idx_sat_snapshots_created (created_at)
- idx_satellite_time (satellite_name, created_at)
Para satellites:
- idx_satellites_active (is_active)
- idx_satellites_last_seen (last_seen)
10. Consultas típicas previstas
Estado actual del nodo
SELECT * FROM snapshots ORDER BY created_at DESC LIMIT 1;
Evolución de un satélite
SELECT * FROM satellite_snapshots WHERE satellite_name = 'eu1' ORDER BY created_at;
Top satélites por almacenamiento
SELECT satellite_name, storage_used_bytes FROM satellite_snapshots s JOIN snapshots sn ON s.snapshot_id = sn.id WHERE sn.created_at = ( SELECT MAX(created_at) FROM snapshots ) ORDER BY storage_used_bytes DESC;
11. Tablas futuras previstas
reports
Para guardar informes narrativos generados por el reporter.
Campos previstos:
- id
- snapshot_id
- created_at
- report_text
report_embeddings
Para búsquedas semánticas futuras usando pgvector.
Campos previstos:
- id
- report_id
- embedding
- created_at
anomaly_events
Para eventos anómalos detectados automáticamente.
Campos previstos:
- id
- snapshot_id
- satellite_id
- severity
- description
- created_at
12. Valor didáctico del proyecto
Este proyecto sirve como caso de estudio completo porque conecta:
- infraestructura real;
- red distribuida;
- Docker;
- API REST;
- n8n;
- PostgreSQL;
- modelado de datos;
- series temporales;
- IA aplicada;
- reporting automático;
- análisis económico.
No es una demo abstracta.
Parte de un nodo real, con datos reales, tráfico real, pagos reales y problemas reales.
13. Narrativa de presentación recomendada
Estructura sugerida:
- Presentar Storj como red distribuida.
- Explicar el papel del SNO.
- Presentar el nodo Nexus como experimento.
- Mostrar cómo el disco se llenó y cambió el comportamiento.
- Explicar por qué mirar la dashboard manualmente no escala.
- Introducir Storj Observatory.
- Explicar la arquitectura n8n -> PostgreSQL -> IA.
- Mostrar el esquema de base de datos.
- Explicar qué análisis permitirá hacer.
- Cerrar con la idea principal:
La IA no sustituye la observabilidad; la vuelve comprensible.
14. Frase de cierre
Storj Observatory convierte un nodo doméstico de almacenamiento distribuido en un pequeño laboratorio de observabilidad: captura datos, conserva histórico, permite análisis y usa IA para transformar métricas técnicas en conocimiento operativo.